1. 파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습 p601~623
2. Shusen Wang - Vision Transformer for Image Classification (유튜브)
3. 고려대학교 DSBA - [Paper Review] ViT
자연어 처리에서의 트랜스포머는 컴퓨터 비전에서도 많은 영향을 주었는데,
이전 컴퓨터비전 관련 연구는 합성곱 신경망에 트랜스포머 모델의 셀프 어텐션 모듈을 착용한 모델이 많았지만,
ViT(Vision Transformer)는 트랜스포머 구조 자체를 컴퓨터비전 분야에 적용한 첫 번째 연구다.
CNN 모델의 합성곱 계층 방법은 이미지 분류를 위해서 지역 특징을 추출했다면
ViT는 셀프 어텐션을 사용해 전체 이미지를 한 번에 처리하는 방식으로 구현한다.
BERT와 ViT 모델은 모두 트랜스포머 구조를 갖는데, 입력 데이터를 만드는 과정은 서로 다르다.
ViT 모델은 이미지가 격자로 작은 단위의 이미지 패치로 나뉘어 순차적으로 입력된다.
ViT 모델에 사용되는 입력 이미지 패치는 왼쪽에서 오른쪽, 위에서 아래로 표현된 시퀀셜 배열을 가정한다
합성곱 모델과 ViT 모델 비교
합성곱 신경망과 트랜스포머는 이미지 특징을 잘 표현하는 임베딩을 만들고자 하는 목적은 같음
합성곱 신경망의 임베딩은 이미지 패치 중 일부만 선택하여 학습하며, 이를 통해 이미지 전체의 특징을 추출함
반면 ViT 임베딩은 이미지를 작은 패치들로 나눠 각 패치 간의 상관관계를 학습함.
이를 위해 셀프 어텐션 방법을 사용해
모든 이미지 패치가 서로에게 주는 영향을 고려해
이미지의 전체 특징을 추출함.
그러므로 ViT는 모든 이미지 패치가 학습에 관여하며 높은 수존의 이미지 표현을 제공함
좁은 수용 영역(Receptive Field, RF)을 가진 합성곱 신경망은
전체 이미지 정보를 표현하는 데 수많은 계층이 필요하지만,
트랜스포머 모델은 어텐션 거리(Attention Distance)를 계산하여
오직 한 개의 ViT 레이어로 전체 이미지 정보를 쉽게 표현할 수 있다.
ViT는 픽셀 단위로 처리하는 합성곱 모델과 달리 패치 단위로 이미지를 처리하기 때문에
더 작은 모델로도 높은 성능을 얻을 수 있다는 장점이 있다.
ViT 모델은 입력 이미지의 크기가 고정되어 있어
크기가 다른 이미지를 처리하려면 이미지 크기를 맞추는 전처리가 필요하며,
합성곱 신경망이 이미지의 공간적인 위치 정보를 고려하는 데 비해
ViT는 패치 간의 상대적인 위치 정보만 고려하기 때문에 이미지 변환에 취약할 수 있다
ViT의 귀납적 편향
편향의 개념이 생소함..
ViT 모델
입력 이미지를
트랜스포머 구조에 맞게 일정한 크기의 패치로 나눈 다음
각 패치를 벡터 형태로 변환하는
패치 임베딩(Patch Embedding)과
각 패치와의 관계를 학습하는 인코더(Encoder) 계층으로 구성됨
패치 임베딩과 인코더 계층을 통해
이미지의 특징을 추출하고 분류나 회귀와 같은 작업에 맞는 출력값으로 변환해 사용함
패치 임베딩
패치 임베딩(Patch Embedding)은 입력 이미지를 작은 패치로 분할하는 과정을 말함
작은 패치로 분할하기 위해서는 이미지 크기를 맞추는 전처리가 수행돼야 함
크기에 맞게 정방향 크기로 이미지 크기를 조절함
이미지 크기를 일정한 크기로 변경했다면
전체 이미지를 패치 크기로 분할해 시퀀셜 배열을 만듦
이때 합성곱 신경망의 계층을 활용함
인코더 계층
모델 실습
허깅 페이스 라이브러리와 FashionMNIST 데이터세트를 활용해
ViT 모델을 미세 조정해본다
FashionMNIST 데이터세트는 기존의 MNIST 데이터세트보다 더 복잡한 이미지 분류 문제를 해결하기 위해 만들어짐
FashionMNIST 데이터세트는 의류 이미지를 담고 있는 데이터세트로
총 10개의 클래스와 60000개의 훈련 데이터세트, 10000개의 테스트 데이터세트로 구성된다
간단한 실습을 위해 학습 데이터를 10000개, 테스트 데이터를 1000개로 샘플링한다
itertools 모듈에서 chain 함수를 가져옵니다. chain 함수는 여러 개의 iterable을 하나의 iterable로 결합합니다.
from collections import defaultdict
collections 모듈에서 defaultdict를 가져옵니다. defaultdict는 기본값을 가진 딕셔너리를 생성하는 클래스입니다.
from torch.utils.data import Subset
PyTorch의 데이터셋을 사용하기 위해 Subset 클래스를 가져옵니다. 이 클래스는 데이터셋의 일부를 나타내는 서브셋을 만들어줍니다.
논문 관련 강의 내용
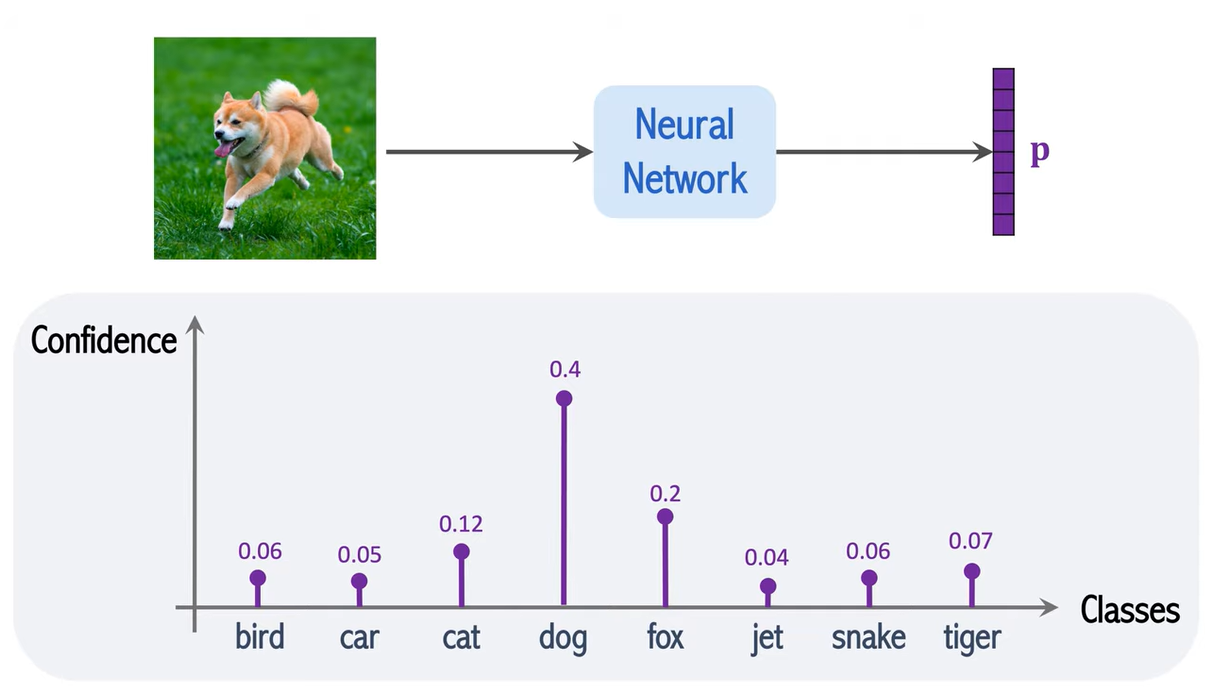
강아지의 사진을 Neural Network에 넣으면 벡터 p값을 내놓은다.
이 벡터 p값은 이미지 분류(image classification)의 결과다.
벡터 p의 각각의 요소(element)는 class와 연관 되어 있다.
그래서 만약에 8개의 class가 있으면 벡터 p는 8차원이다.
밑에 그래프처럼 각각의 요소들은 0~1사이의 값을 가지며
총합은 1로 수렴한다.
데이터셋이 클수록 ResNet보다 더 효율적인 성능을 보임
ViT is based on Transformer (for NLP)
일단 처음에 ViT 모델에 데이터를 돌리기 위해서는 이미지를 partition해야함 (into Patches)


이미지를 partition할 때 sliding window를 이용하여 매번 몇 픽셀씩 움직인다
여기서 stride란 how many pixels the sliding window moves each time
위와 같은 상태에서 User Specifies 조건에 patch size가 16x16인데
stride를 1x1로 하면 patch가 너무 많아져서 계산량이 많아질 것임 (heavy computation)

9개의 patch로 나눠졌다고 생각해보자.
모든 patch들은 또 각각의 rgb 채널이 있는 이미지를 형성한다
a patch is an order 3 tensor
이렇게 9개의 patch들로 쪼갰으면 patch들을 vectorize하면 좋을 것 같다
vectorization이란 tensor를 벡터로 reshape 하는 것을 의미한다

저 patches 부분 이해 못함..
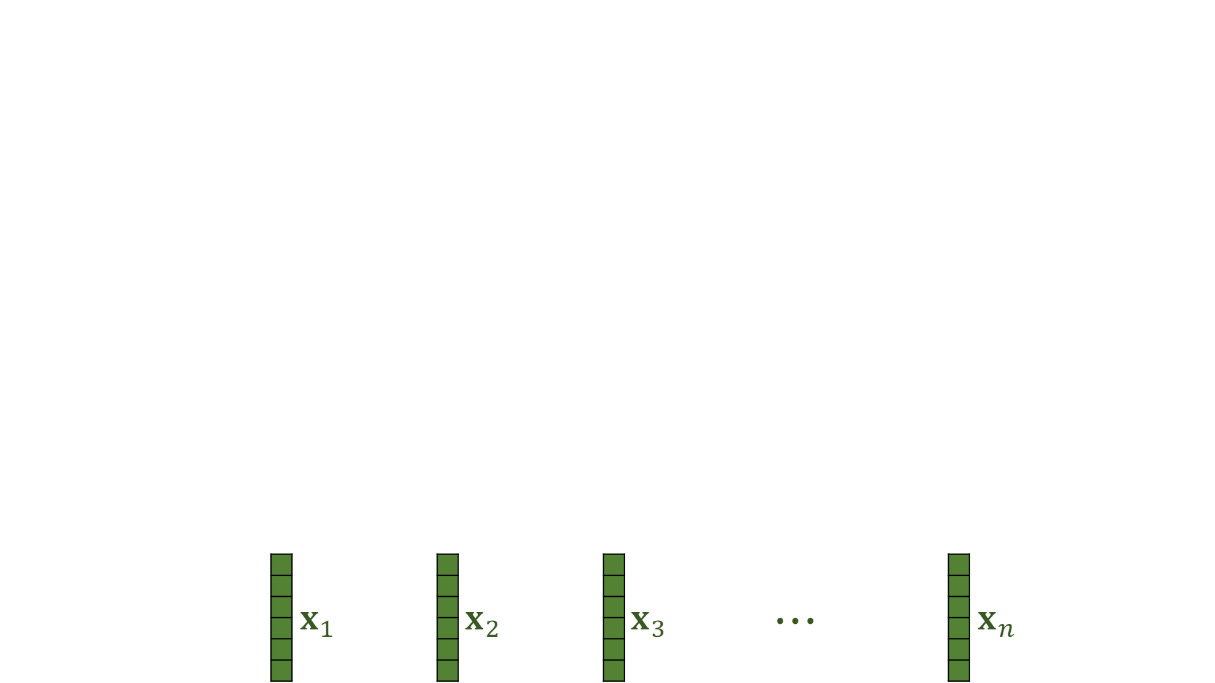
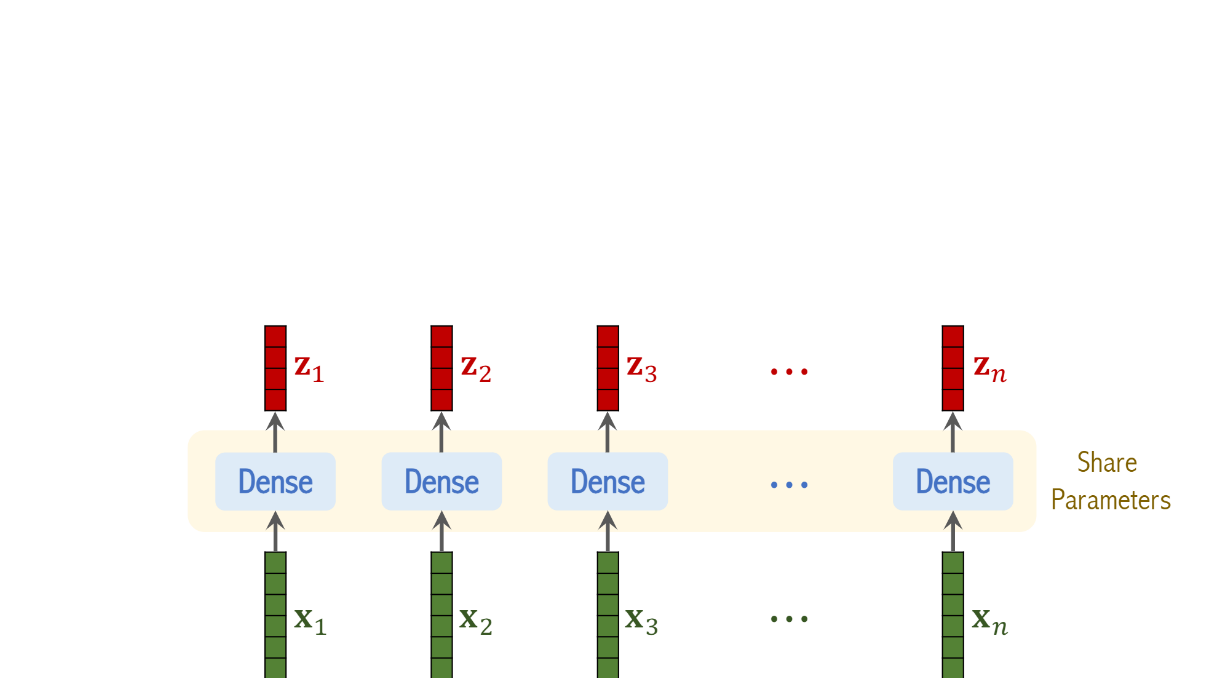
n개의 patches들로 나눠지고 이 patches들이 n개의 벡터로 나눠졌다고 생각을 해보자
이때 각각의 vector에서 dense layer을 적용하면
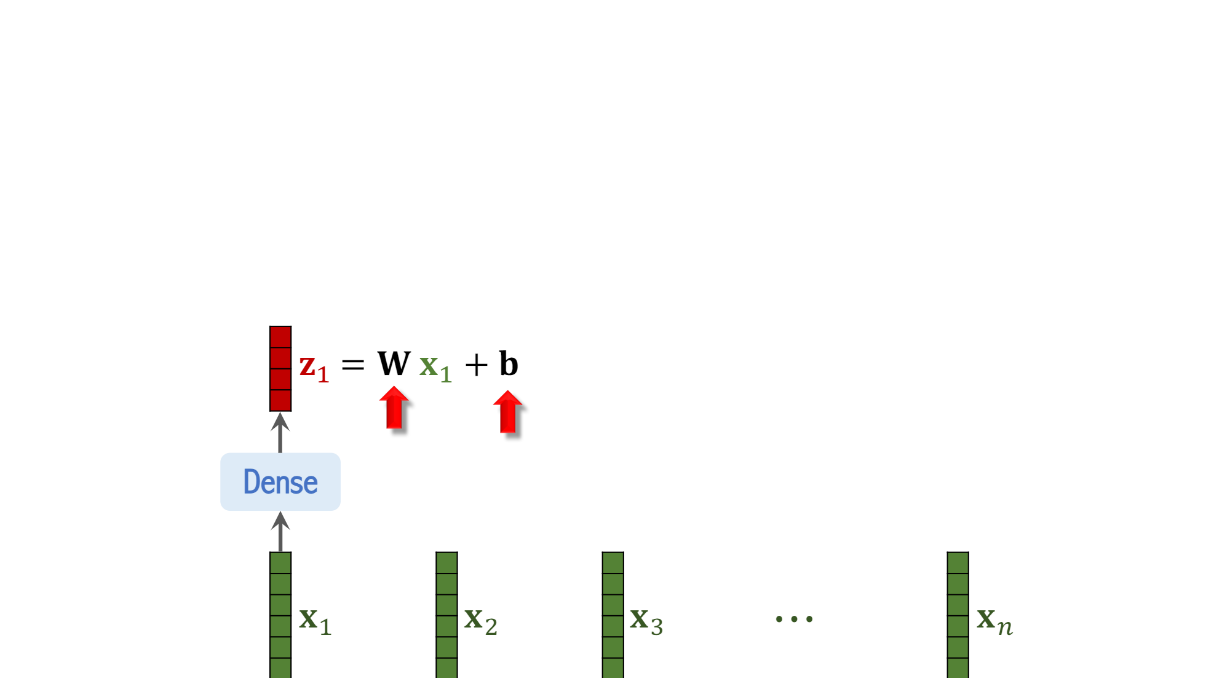
이러한 output이 나오는데
이때 linear activation function이 적용된 것이 아니므로
dense layer은 선형함수임을 알 수 있다. (linear functions)
W는 행렬이고 b는 벡터인데 이는 training data를 통해서 알 수 있는 값들이다
그리고 이 dense layer은 모든 벡터에서 동일한 parameter W, b를 갖는다
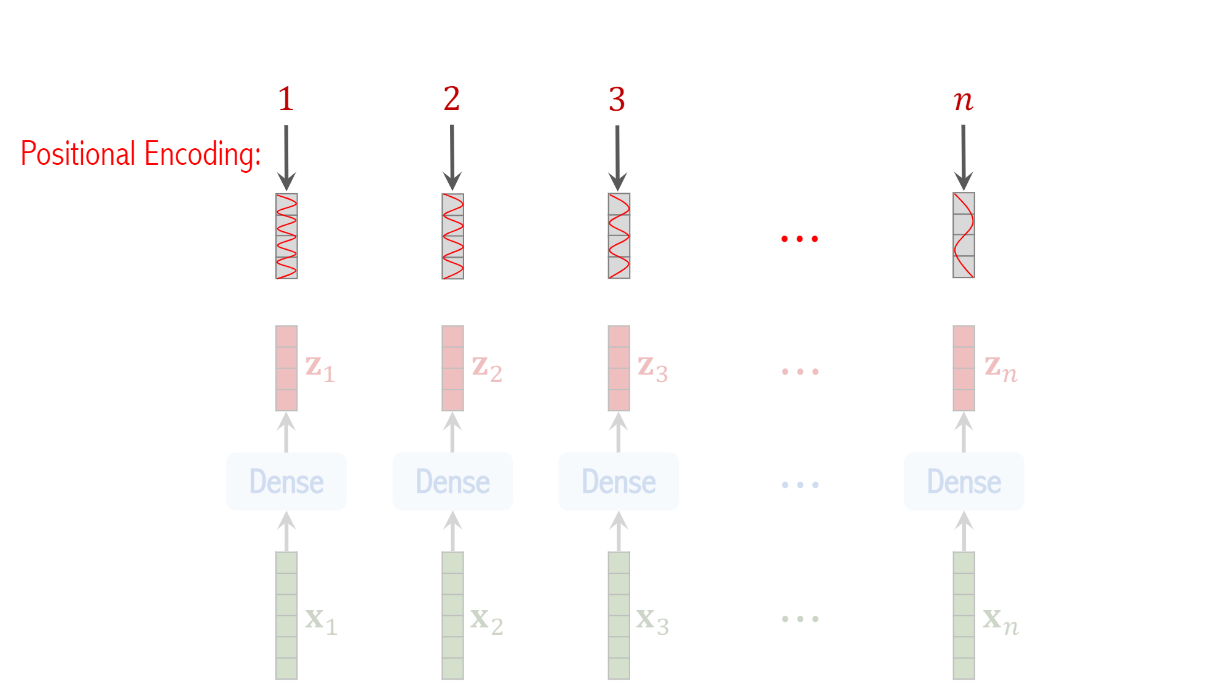
We need to add positional encoding to vector z1 to zn
the input image is split into n patches
each patch has a position which is an integer between 1 and n
positional encoding maps that integer into a vector
the shape of the vector is the same as z
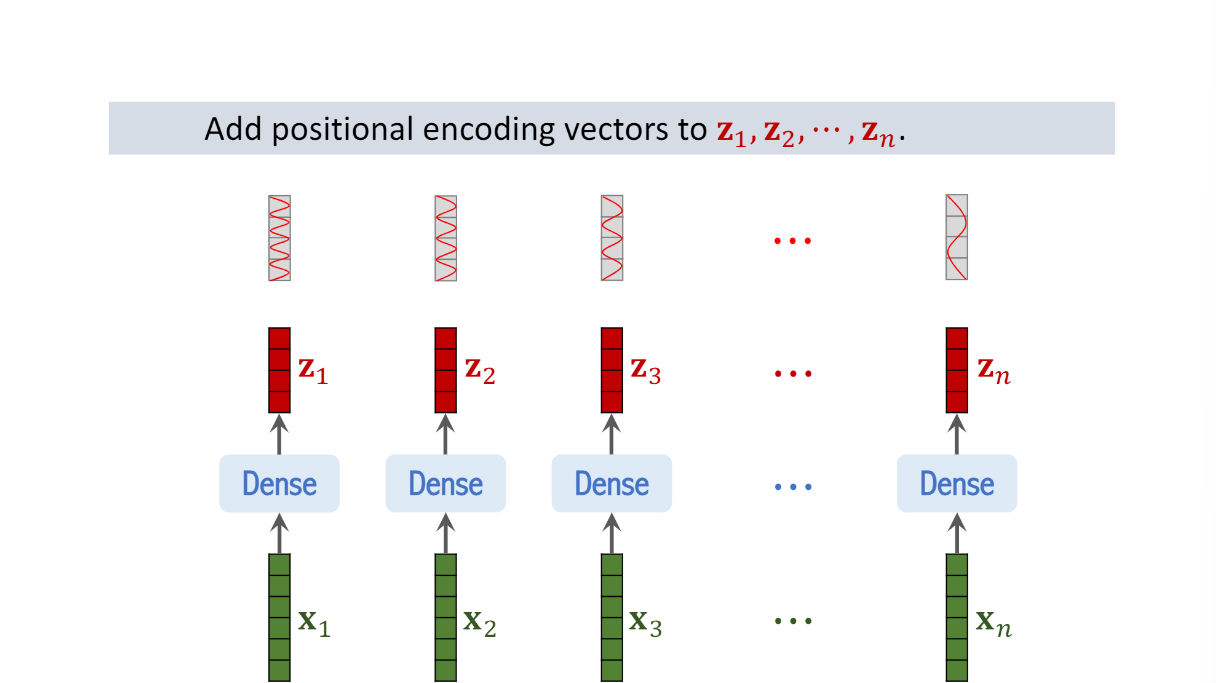
Add the positional encoding vectors to the z vectors
This way, a z vector captures both the content and the position of a patch
The ViT paper empirically demonstrated the benefit of using positional encoding
Without position encoding the accuracy decreases by three percent
The paper tried several positional encoding methods
Those methods lead to almost the same accuracy
so it is okay to use any kind of positional encoding
왜 positional encoding은 중요할까?




두 번째 이미지는 patch들을 재배열하여 그림을 나타냈다. 그래서 당연히 강아지 그림은 두 개가 서로 다르게 됐는데
z벡터를 swapping 하는 것은 final output of transformer에 영향을 주지 않을 것임
if the z vectors do not contain the positional encoding
그러면 transformer 입장에서는 두 이미지가 똑같다고 판단할 것임
당연히 이것은 올바르지 않은 판단이기 때문에
positional information을 patches에 붙히고 z vectors에 positional encoding 을 붙히는 것임
이렇게 되면 만약에 이미지가 뒤죽 박죽 됐을 때
positional encoding 이 바뀔테니깐
그러면 transformer의 output이 달라질 것이다
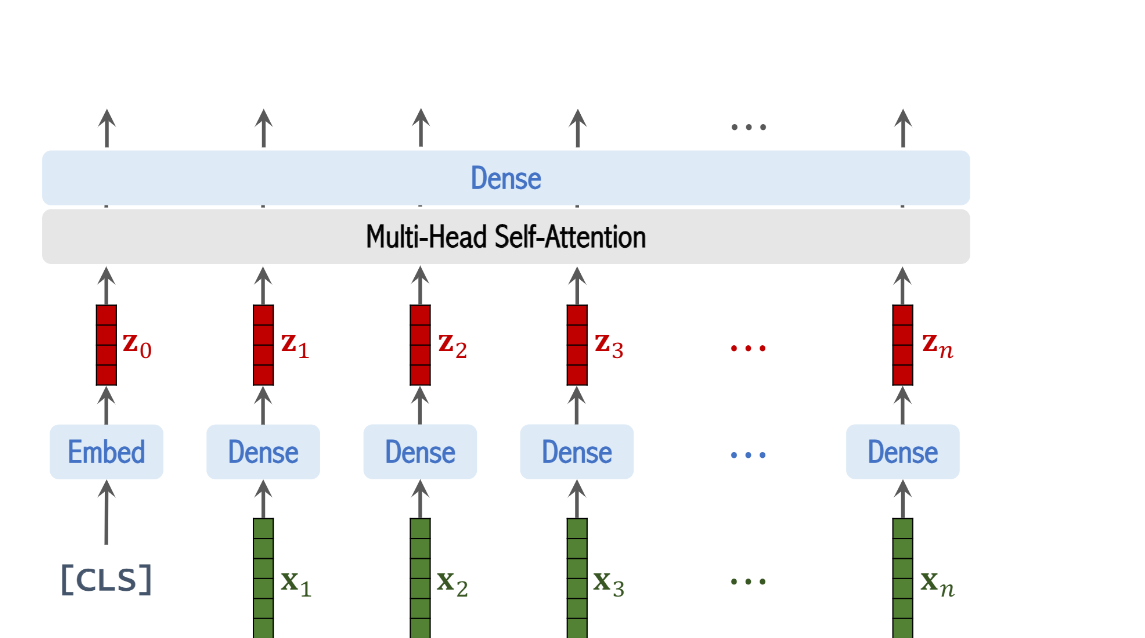
(복습 : 여기에서 z1~zn 벡터의 결과는 linear transformation과 positional encoding 의 결과다
they are the representations of the n patches
they capture both the content and the positions of the patches)
We use the CLS token for classification
Then the embedding layer takes the input of the CLS token and outputs vector z0
이때 z0 has the same shape as the other z vectors
We use this CLS token because the output of transformer in this position will be used for classification
(BERT 모델에 CLS 관련된 내용이 나오나봄!)
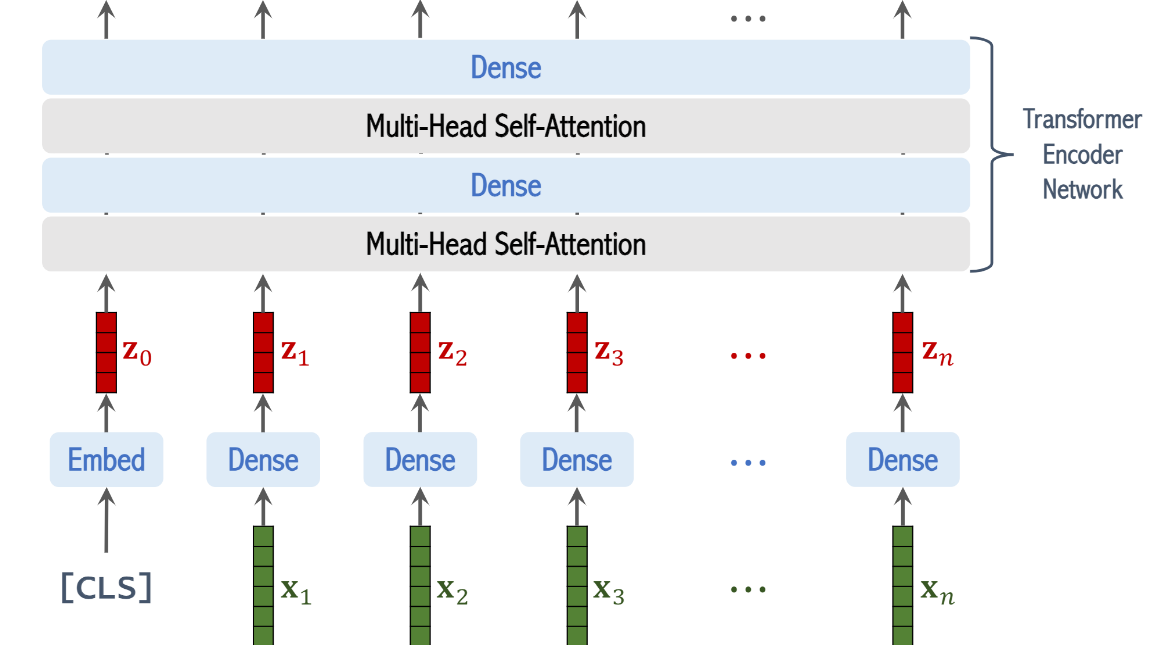
the output of this multi-head self-attention layer are sequence of n plus 1 vectors
the output of the dense layer are sequence of n plus 1 vectors
you can add many self attention layers and dense layers one by one if you want
besides from the layers
transformer actually uses skip connection and normalization
there are standard tricks for improving performance
멀티헤드 셀프 어텐션 레이어와 덴스 레이어는 트랜스포머의 encoder 네트워크를 구성합니다.
이에 대한 output은 n+1 벡터의 시퀀스들이다
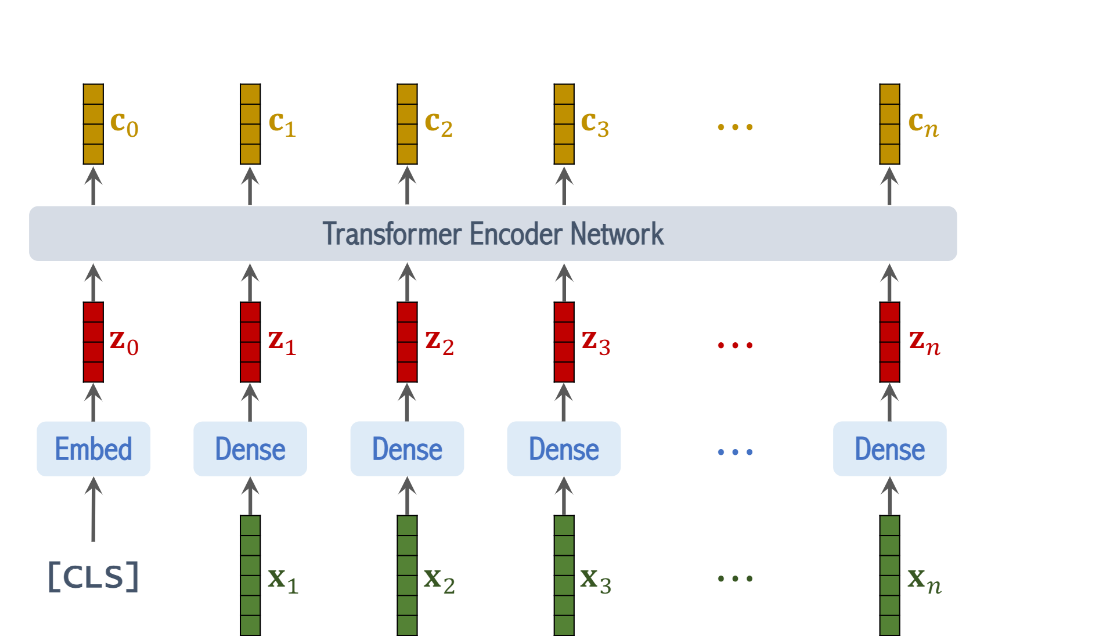
c0~cn은 transformer의 output임.
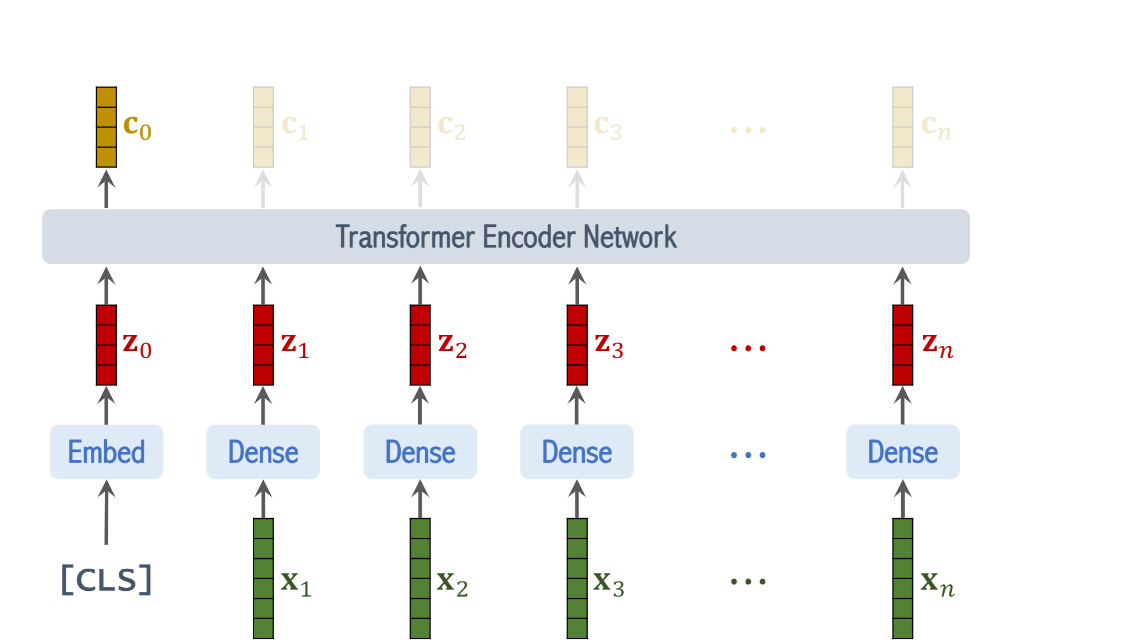
classification task를 수행하기 위해서는 우리는 c1~cn의 벡터는 필요 없어서 무시해도 좋다
우리가 필요한 것은 vector c0이다
vector c0는 feature vector extracted from the image
the classification is based on c0
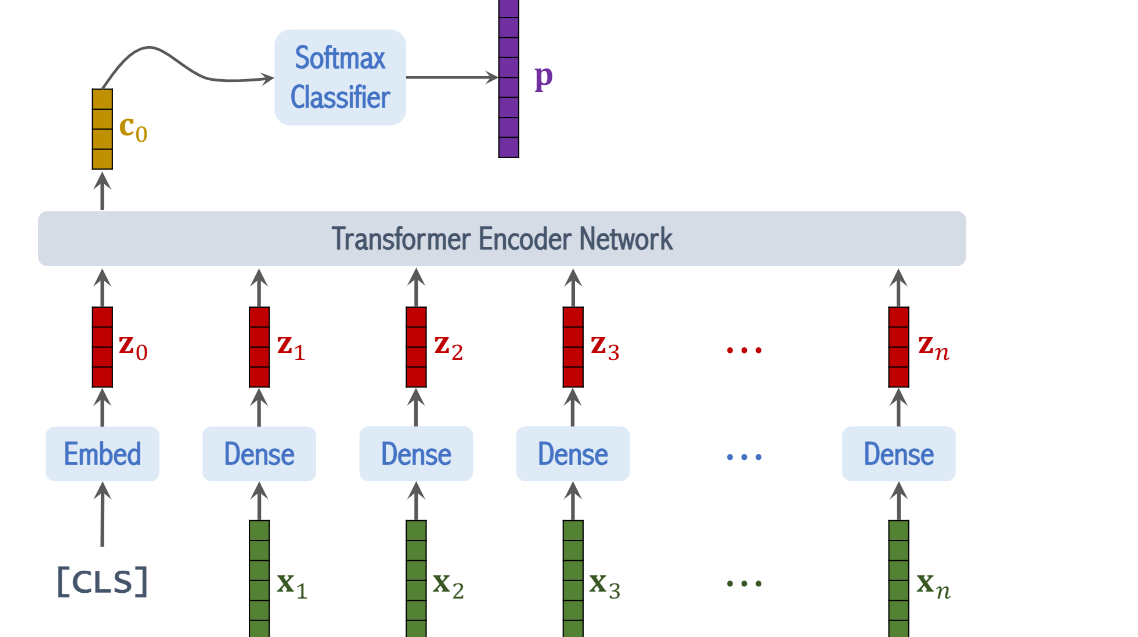
그래서 벡터 c0를 softmax classifier에 집어 넣으면 벡터 p가 나오게 되고
이 벡터의 shape은 class의 수와 같다
만약에 data set이 8개의 class를 가지면
p는 8차원이다
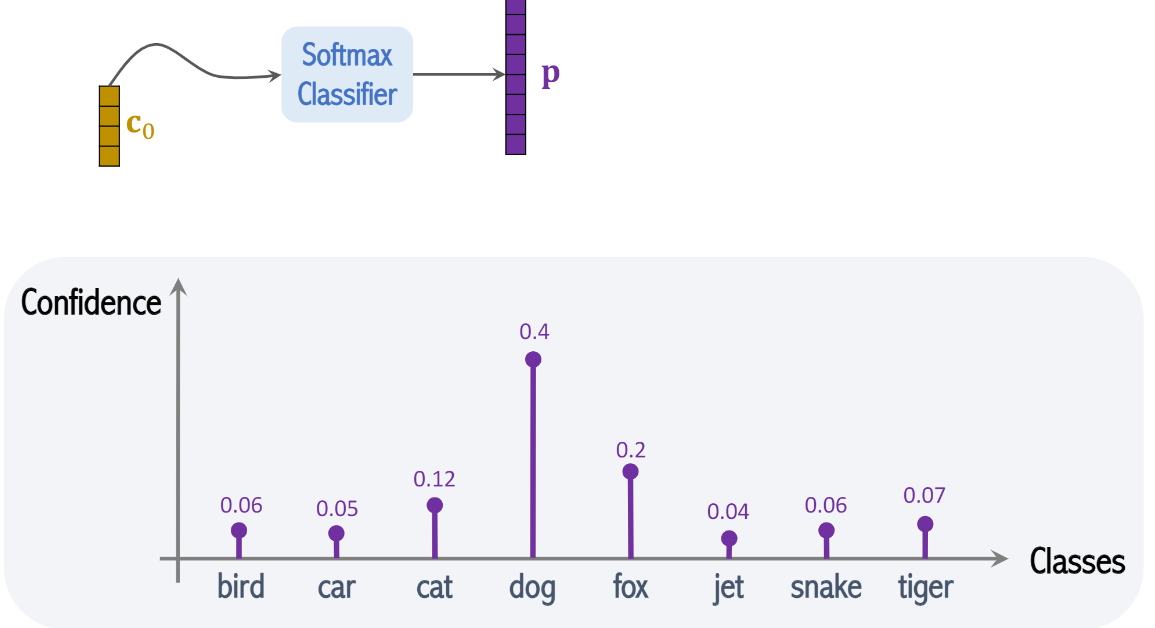
p의 값을 나타낸 그래프임
during training we compute the cross entropy of vector p and the ground truth
then compute the gradient of the cross entropy loss with respect to the model parameters
and perform gradient descent to update the parameters
이제 ViT의 구조를 살펴봤으니
dataset을 train 시켜봐야한다
(Next step is to train the model on image data)
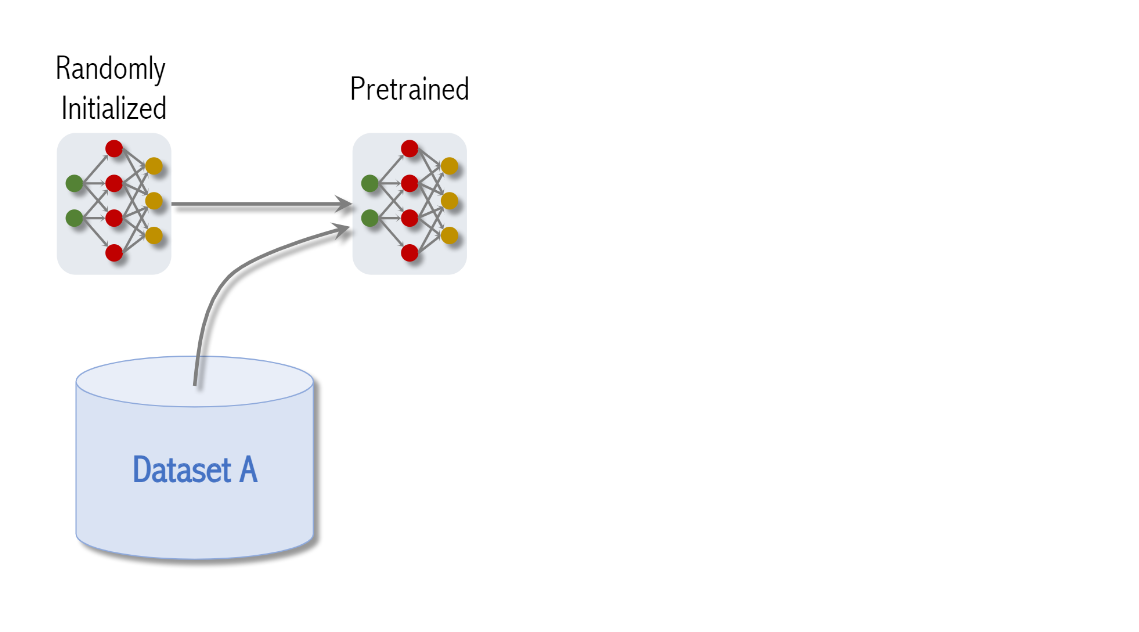
일단 모델을 random intialize(초기화)한 후
train the model on data set A
이때 이 데이터세트는 large scale data set이여야 한다
이것은 pretraining 이라고 부른다
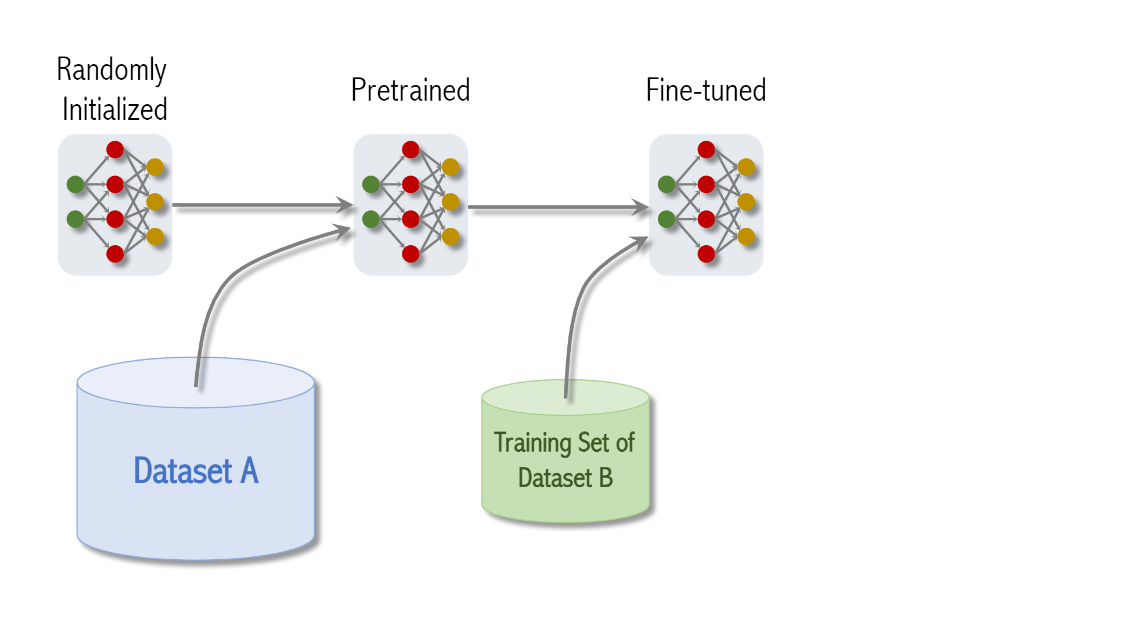
그래서 앞서 pretrain한 모델을 가지고
dataset B로 training을 또 시킨다
보통의 경우 dataset A보다는 크기가 작고
이러한 과정을 fine tuning이라고 한다
dataset B는 ImageNet이 될 수 있음
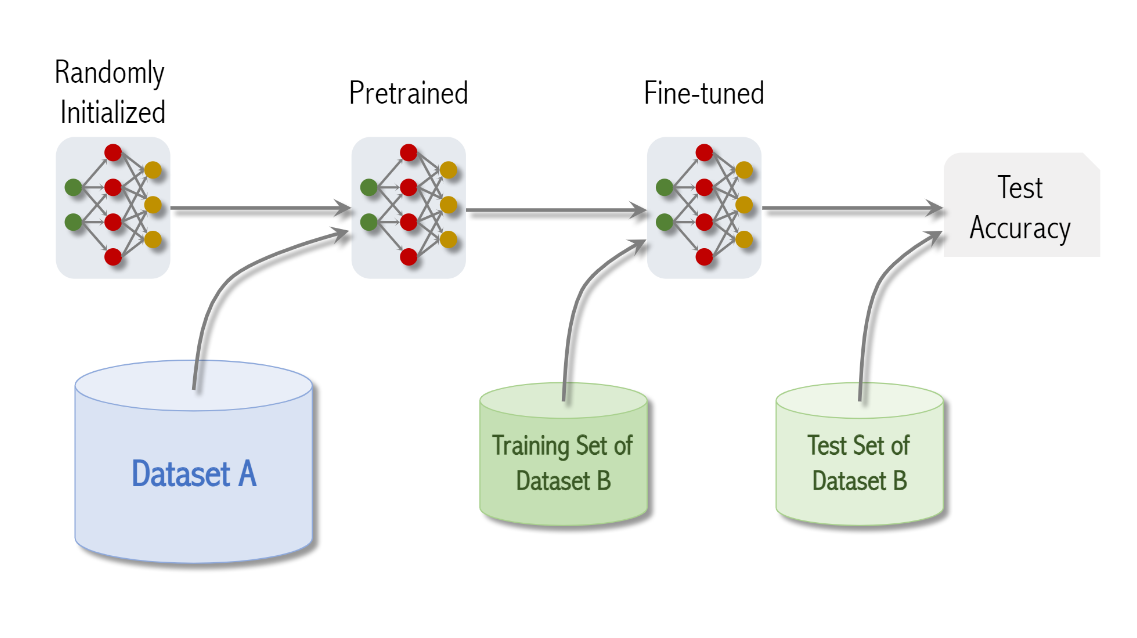
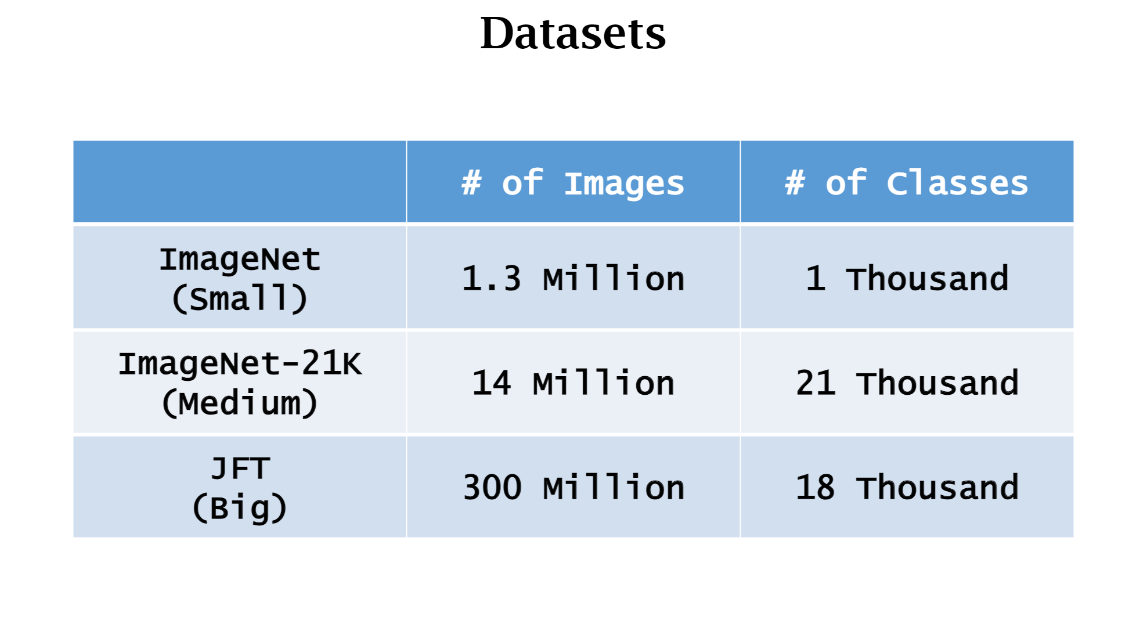

Dataset B is the target data set
그래서 test accuracy를 구하기 위해서 data set b를 evaluation matrix로 사용함
데이터양이 엄청 클수록 resnet보다 좋음

transformer requires very large data for pretraining
the bigger the pre-training data set
the greater the advantage of transformer over resnet
300M 이상이 더 좋을 듯함
레즈넷의 경우 100m이던 300m이던 차이가 없음
the accuracy of resnet does not improve
as the number of samples grows from 100m to 300m
in sum ViT requires huge data for pre-training
Transformer is an advantage over cnn only when the data set for pretuning is sufficiently large
300m 이미지도 부족함 (not enough)
https://www.youtube.com/watch?v=HZ4j_U3FC94
https://github.com/wangshusen/DeepLearning?tab=readme-ov-file